| 机器学习基础线性回归 | 您所在的位置:网站首页 › tableau 多元线性回归 › 机器学习基础线性回归 |
机器学习基础线性回归
|
线性回归
步骤: 明确定义所要解决的问题——网店销售额的预测在数据的收集与预处理环节,分五个环节完成数据的预处理工作,分别如下 (1)收集数据— 需要提供的网店的相关记录 (2)将收集到的数据可视化,显示出来看一看 (3)做特征工程,使数据更容易被机器处理 (4)拆分数据集为训练集和测试集 (5)做特征缩放,把数据值压缩到比较小的区间选择机器学习的模型环节 (1)确定机器学习的算法——这里也就是线性回归算法 (2)确定线性回归算法的假设函数 (3)确定线性回归算法的损失函数通过梯度下降训练机器,确定模型内部参数的过程进行超参数调试和性能优化 一、问题定义:网站广告该如何投放先看数据: 定义问题: 各种广告和商品销售额的相关度如何。各种广告和商品销售额之间体现出一种什么关系。哪一种广告对于商品销售额的影响最大。分配特定的广告投放金额,预测出未来的商品销售额。在机器学习中,如果只包括一个自变量和一个因变量,且两者的关系可用一条直线近似表示,这种回归分析就称为一元线性回归分析。 如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。 二、数据的收集和预处理 1.收集网店销售额数据advertising.csv 需要的可以去网上搜一搜。
通过散点图两两一组显示商品销售额和各种广告投放金额之间的对应关系。 #显示销量和各种广告投放量的散点图 sns.pairplot(df_ads, x_vars=['wechat', 'weibo', 'others'], y_vars='sales', height=4, aspect=1, kind='scatter') plt.show()
下面把df_ads中的微信公众号广告投放金额字段读入一个NumPy数组X,也就是清洗了其他两个特征字段,并把标签读入数组y: X = np.array(df_ads.wechat) #构建特征集,只含有微信广告一个特征 y = np.array(df_ads.sales) #构建标签集,销售金额 print ("张量X的阶:",X.ndim) print ("张量X的形状:", X.shape) print ("张量X的内容:", X)
进行张量变形: X = X.reshape((len(X),1)) #通过reshape函数把向量转换为矩阵,len函数返回样本个数 y = y.reshape((len(y),1)) #通过reshape函数把向量转换为矩阵,len函数返回样本个数print ("张量X的阶:",X.ndim) print ("张量X的形状:", X.shape) print ("张量X的内容:", X)
通过Sklearn库中的preprocessing (数据预处理)工具中的Min Max Scaler可以实现数据的归一化。 这里定义一个归一化函数: def scaler(train, test): #定义归一化函数,进行数据压缩 min = train.min(axis=0) #训练集最小值 max = train.max(axis=0) #训练集最大值 gap = max - min #最大值和最小值的差 train -= min #所有数据减最小值 train /= gap #所有数据除以大小值差 test -= min #把训练集最小值应用于测试集 test /= gap #把训练集大小值差应用于测试集 return train, test #返回压缩后的数据不能使用测试集中数据信息进行特征缩放中间步骤中任何值的计算。 对特征和标签进行归一化: X_train,X_test = scaler(X_train,X_test) #对特征归一化 y_train,y_test = scaler(y_train,y_test) #对标签也归一化查看归一化后的散点图: #用之前已经导入的matplotlib.pyplot中的plot方法显示散点图 plt.plot(X_train,y_train,'r.', label='Training data') plt.xlabel('Wechat Ads') # x轴Label plt.ylabel('Sales') # y轴Label plt.legend() # 显示图例 plt.show() # 显示绘图结果
这个简单的模型就是一元线性函数:y=ax+b a就相当于w:权重,b就相当于偏置。 weight是权重,bias是偏置。 2.假设(预测)函数——h(x)y’=wx+b h(x)=wx+b 注意: y’指的是所预测出的标签,读作y帽(y-hat)或y撇h(x)就是机器学习所得到的函数模型,他能根据输入的特征进行标签的预测。 我们就把它称为假设函数。有时也叫做预测函数。所以机器学习的具体目标就是确定假设函数h(x): 确定b,也就是y轴截距,这里称为偏置。确定w,也就是斜率,这里称为特征x的权重。 3.损失(误差)函数——L(w,b)损失:是对糟糕预测的惩罚。损失也就是误差,也称为成本或代价 损失函数(loss function)L(w,b)就是用来计算平均损失的。 如果平均损失小,参数就好;如果平均损失大,模型或者参数就还要继续调整。 机器学习中的损失函数,主要包括: 用于回归的损失函数。 – 均方误差(MSE)函数,也叫平方损失或L2损失函数 – 平均绝对误差(MAE)函数,也叫L1损失函数 – 平均偏差误差函数用于分类的损失函数 – 交叉熵损失函数 – 多分类SVM损失函数线性回归模型的常用损失函数——均方误差函数。 手工定义一个均方误差函数: def loss_function(X, y, weight, bias): # 手工定义一个MSE均方误差函数 y_hat = weight*X + bias # 这是假设函数,其中已经应用了Python的广播功能 loss = y_hat-y # 求出每一个y’和训练集中真实的y之间的差异 cost = np.sum(loss**2)/(2*len(X)) # 这是均方误差函数的代码实现 return cost # 返回当前模型的均方误差值随便定义两组参数,看看其均方误差大小: print ("当权重5,偏置3时,损失为:", loss_function(X_train, y_train, weight=5, bias=3)) print ("当权重100,偏置1时,损失为:", loss_function(X_train, y_train, weight=100, bias=1))
梯度下降是整个机器学习的精髓,堪称机器学习之魂。在我们身边发生的种种机器学习和深度学习的奇迹,归根结底哦都是拜梯度下降所赐。 2.凸函数确保有最小损失点凸函数的图像会流畅、连续的形成相对于y轴的全局最低点,也就是说存在着全局最小损失点。这也是此处选择MSE作为线性回归的损失函数的原因。 梯度下降的过程就是在程序中一点点变化参数w和b,使L,也就是损失值,逐渐趋近最低点(也就是称为机器徐熙中的最优解) 要想快速趋近最小损失点,秘密武器就是导数。倒数描述了函数在某点附近的变化率,这正是进一步猜测更好的权重时所需要的全部内容。 程序中用梯度下降法通过求导来计算损失函数曲线在起点处的梯度,此时,梯度就是损失曲线导数的矢量,他们可以让我们了解距离目标“更远”或“更近” 如果求导后梯度为正值,则说明L正在随着w增大而增大,应该减小w,以得到更小的损失。如果求导后梯度为负值,则说明L正在随着w增大而减小,应该增大w,以得到更小的损失。梯度下降法会随着负梯度的方向走一步,以降低损失。 梯度下降公式: y_hat = w*X + b # 这个是向量化运行实现的假设函数 loss = y_hat-y # 这是中间过程,求得的是假设函数预测的y和真正的y值间的差值 derivative_w = X.T.dot(loss)/len(X) # 对权重求导, len(X)是样本总数 derivative_b = sum(loss)*1/len(X) # 对偏置求导 4.学习速率梯度具有两个特征: 方向(也就是梯度的正负)大小(也就是切线倾斜的幅度)我们已经知道权重w应该往哪个方向走,下一个问题就是以多快的速度,这在机器学习中被称为“学习速率”,记作α,读作alpha。 学习速率乘以损失曲线求导之后的微积分,就是一次梯度变化的步长。 代码实现: w = w - lr*derivative_w # 结合下降速率alpha更新权重 b = b - lr*derivative_b # 结合下降速率alpha更新偏置下面给出梯度下降的完整代码(已经封装在一个自定义的函数gradiant_descent中): def gradient_descent(X, y, w, b, lr, iter): # 定义一个实现梯度下降的函数 l_history = np.zeros(iter) # 初始化记录梯度下降过程中损失的数组 w_history = np.zeros(iter) # 初始化记录梯度下降过程中权重的数组 b_history = np.zeros(iter) # 初始化记录梯度下降过程中偏置的数组 for i in range(iter): # 进行梯度下降的迭代,就是下多少级台阶 y_hat = w*X + b # 这个是向量化运行实现的假设函数 loss = y_hat-y # 这是中间过程,求得的是假设函数预测的y和真正的y值间的差值 derivative_w = X.T.dot(loss)/len(X) # 对权重求导, len(X)是样本总数 derivative_b = sum(loss)*1/len(X) # 对偏置求导 w = w - lr*derivative_w # 结合下降速率alpha更新权重 b = b - lr*derivative_b # 结合下降速率alpha更新偏置 l_history[i] = loss_function(X, y, w,b) # 梯度下降过程中损失的历史 w_history[i] = w # 梯度下降过程中权重的历史 b_history[i] = b # 梯度下降过程中偏置的历史 return l_history, w_history, b_history # 返回梯度下降过程数据注意,当梯度下降程序实现时,会被置入一个循环中,需要观察损失曲线是否已经开始收敛。需要根据具体情况及时调整。 五、实现一元线性回归模型并调试超参数 1.权重和偏置的初始值通过下面代码设置初始参数值: # 首先确定参数的初始值 iterations = 225; # 迭代250次 alpha = 0.5; # 此处初始学习速率设为0.5, 如果调整为1,你会看到不同的结果 weight = -5 # 权重 bias = 3 # 偏置 # 计算一下初始权重和偏置值所带来的损失 print ('当前损失:',loss_function(X_train, y_train, weight, bias))
下面就基于这个平均损失比较大的初始参数值,进行梯度下降,也就是开始训练模型,拟合函数。 # 根据初始参数值,进行梯度下降,也就是开始训练机器,拟合函数 loss_history, weight_history, bias_history = gradient_descent( X_train, y_train, weight, bias, alpha, iterations)绘制损失曲线: plt.plot(loss_history,'g--',label='Loss Curve') plt.xlabel('Iterations') # x轴Label plt.ylabel('Loss') # y轴Label plt.legend() # 显示图例 plt.show() # 显示损失曲线这个时候α是没有设定的,所以损失值越来越大,而线性函数图像根本就灭有与数据集形成拟合。 3.调试学习速率当我们反复调试,当α=0.5时,情况表较好。 iterations = 225; # 迭代250次 alpha = 0.5; # 此处初始学习速率设为0.5, weight = -5 # 权重 bias = 3 # 偏置 loss_history, weight_history, bias_history = gradient_descent( X_train, y_train, weight, bias, alpha, iterations) plt.plot(loss_history,'g--',label='Loss Curve') plt.xlabel('Iterations') # x轴Label plt.ylabel('Loss') # y轴Label plt.legend() # 显示图例 plt.show() # 显示损失曲线
下面输出α=0.5时,迭代200次之后的损失值,及w和b的值: print ('当前损失:',loss_function(X_train, y_train, weight_history[-1], bias_history[-1])) print ('当前权重:',weight_history[-1]) print ('当前偏置:',bias_history[-1])
绘制训练集与测试集的损失曲线: # 同时绘制训练集和测试集损失曲线 loss_test ,a , b = gradient_descent(X_test, y_test, weight, bias, alpha, iterations) plt.plot(loss_history,'g--',label='Traning Loss Curve') plt.plot(loss_test,'r',label='Test Loss Curve') plt.xlabel('Iterations') # x轴Label plt.ylabel('Loss') # y轴Label plt.legend() # 显示图例 plt.show()
损失函数: #定义损失函数 def loss_function(X, y, W): # 手工定义一个MSE均方误差函数 y_hat = X.dot(W.T) # 点积运算 loss = y_hat.reshape((len(y_hat),1))-y # 中间过程,求出当前W和真值的差值 cost = np.sum(loss**2)/(2*len(X)) # 这是均方误差函数的代码实现 return cost # 返回当前模型的均方误差值梯度下降: def gradient_descent(X, y, W, lr ,iter): # 定义一个实现梯度下降的函数 l_history = np.zeros(iter) # 初始化记录梯度下降过程中损失的数组 w_history = np.zeros((iter,len(W))) # 初始化记录梯度下降过程中权重的数组 for i in range(iter): # 进行梯度下降的迭代,就是下多少级台阶 y_hat = X.dot(W.T) # 点积运算 loss = y_hat.reshape((len(y_hat),1))-y # 中间过程,求出当前W和真值的差值 derivative_W = X.T.dot(loss)/(2*len(X)) # 求出多项式的梯度向量 len(X)是样本总数 derivative_W = derivative_W.reshape(len(W)) #转置 W = W-alpha*derivative_W #结合学习速率更新权重 l_history[i] = loss_function(X, y, W) # 梯度下降过程中损失的历史 W_history[i] = W # 梯度下降过程中权重的历史 return l_history, w_history # 返回梯度下降过程数据 3.构建一个线性回归的函数模型 #定义线性回归模型 def linear_regression(X,y,weight,alpha,iterations): loss_history,weight_history = gradient_descent(X,y,weight,alpha,iterations) print("训练最终损失:",loss_history[-1]) #输出最终损失 y_pred = X.dot(weight_history[-1]) #进行预测 traing_acc = 100 - np.mean(np.abs(y_pred - y))*100 #计算准确率 print("线性回归训练准确率:{:.2f}%".format(traing_acc)) #输出准确率 return loss_history,weight_history #返回历史训练记录 4.初始化权重并训练机器 #首先确定参数的初始值 iterations = 300 #迭代300次 alpha = 0.15 #学习效率为0.15 weight = np.array([0.5,1,1,1]) #权重向量,w[0]=bias loss_history, weight_history= linear_regression( X_train, y_train, weight, alpha, iterations) print(loss_history,weight_history) 七、用sklearn库进行线性回归导入数据: import numpy as np #导入NumPy数学工具箱 import pandas as pd #导入Pandas数据处理工具箱 # 读入数据并显示前面几行的内容,这是为了确保我们的文件读入正确性 # 示例代码是在Kaggle中数据集中读入文件,如果在本机中需要指定具体本地路径 df_ads = pd.read_csv('advertising.csv') df_ads.head()画热力图: # 导入数据可视化所需要的库 import matplotlib.pyplot as plt # matplotlib – Python画图工具库 import seaborn as sns # seaborn – 统计学数据可视化工具库 # 对所有的标签和特征两两显示其相关性热力图(heatmap) sns.heatmap(df_ads.corr(), cmap="YlGnBu", annot = True) plt.show() # plt 英文意为plot,就是画图的意思
画散点图: # 显示销量和各种广告投放量的散点图。 sns.pairplot(df_ads, x_vars=['wechat', 'weibo', 'others'], y_vars='sales', height=4, aspect=1, kind='scatter') plt.show()
构建特征集和标签: X = np.array(df_ads.wechat) #构建特征集,只有微信广告一个特征 y = np.array(df_ads.sales) #构建标签集,销售金额 print ("张量X的阶:",X.ndim) print ("张量X的形状:", X.shape) print (X)
数据转置: X = X.reshape(-1,1) #也可以利用索引-1通过reshape函数把向量转换为矩阵 y = y.reshape(-1,1) #也可以利用索引-1通过reshape函数把向量转换为矩阵 print ("张量X的形状:", X.shape) print (X)划分训练集和测试集: # 将数据集进行80%(训练集)和20%(验证集)的分割 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)定义归一化函数: def range_0_1(data_train, data_test): # 定义归一化函数 ,进行数据压缩 # 数据的压缩 min = data_train.min(axis=0) # 训练集最小值 max = data_train.max(axis=0) # 训练集最大值 gap = max - min # 最大值和最小值的差 data_train -= min # 所有数据减最小值 data_train /= gap # 所有数据除以大小值差 data_test -= min #把训练集最小值应用于测试集 data_test /= gap #把训练集大小值差应用于测试集 return data_train, data_test # 返回压缩后的数据对数据进行归一化: X_train,X_test = range_0_1(X_train,X_test) # 对特征归一化 y_train,y_test = range_0_1(y_train,y_test) # 对标签也归一化训练模型: from sklearn.linear_model import LinearRegression #导入线性回归算法模型 model = LinearRegression() #使用线性回归算法 model.fit(X_train, y_train) #用训练集数据,训练机器,拟合函数,确定参数查看预测值: y_pred = model.predict(X_test) #预测测试集的Y值 print ('销量的真值(测试集)',y_test) print ('预测的销量(测试集)',y_pred) print("线性回归预测评分:", model.score(X_test, y_test)) #评估预测结果
导入库和数据集: import numpy as np # 导入NumPy数学工具箱 import pandas as pd # 导入Pandas数据处理工具箱 from keras.datasets import boston_housing #从Keras中导入mnist数据集 #读入训练集和测试集 (X_train, y_train), (X_test, y_test) = boston_housing.load_data()定义均方误差: def cost_function(X, y, W): # 手工定义一个MSE均方误差函数,W此时是一个向量 # X -> 是一个矩阵,形状是(N,4),N是数据集大小,4是特征数量 # W -> 是一个向量,形状是(4,1)(1*) # y_hat = X.dot(weight) # 这是假设函数,其中已经应用了Python的广播功能 # y_hat = np.dot(X,weight) # 也是正确的 y_hat = X.dot(W.T) # 也是正确的 点积运算 h(x)=w_0*x_0 + w_1*x_1 + w_2*x_2 + w_3*x_3 # y_hat = np.dot(X,weight.T) # 也是正确的 # y_hat = weight.dot(X) # 错误 shapes (4,) and (160,4) not aligned: 4 (dim 0) != 160 (dim 0) # y_hat = np.dot(weight,X) # 错误 shapes (4,) and (160,4) not aligned: 4 (dim 0) != 160 (dim 0) loss = y_hat-y # 求出每一个y’和训练集中真实的y之间的差异 cost = np.sum(loss**2)/len(X) # 这是均方误差函数的代码实现 return cost # 返回当前模型的均方误差值定义梯度下降函数: def gradient_descent(X, y, W, lr, iter): # 定义梯度下降函数 l_history = np.zeros(iter) # 初始化记录梯度下降过程中损失的数组 W_history = np.zeros((iter,len(W))) # 初始化权重数组 for iter in range(iter): # 进行梯度下降的迭代,就是下多少级台阶 y_hat = X.dot(W) # 这个是向量化运行实现的假设函数 loss = y_hat-y # 中间过程, y_hat和y真值的差 derivative_W = X.T.dot(loss)/(2*len(X)) #求出多项式的梯度向量 derivative_W = derivative_W.reshape(len(W)) W = W - alpha*derivative_W # 结合下降速率更新权重 l_history[iter] = cost_function(X, y, W) # 损失的历史记录 W_history[iter] = W # 梯度下降过程中权重的历史记录 return l_history, W_history # 返回梯度下降过程数据确定初始值: #首先确定参数的初始值 iterations = 12000; # 迭代12000次 alpha = 0.00001; #学习速率设为0.00001 weight = np.array([0.5,1.2,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1]) # 权重向量 #计算一下初始值的损失 print ('当前损失:',cost_function(X_train, y_train, weight))定义回归模型: # 定义线性回归模型 def linear_regression(X, y, weight, alpha, iterations): loss_history, weight_history = gradient_descent(X, y, weight, alpha, iterations) print("训练最终损失:", loss_history[-1]) # 打印最终损失 y_pred = X.dot(weight_history[-1]) # 预测 traning_acc = 100 - np.mean(np.abs(y_pred - y)/y)*100 # 计算准确率 print("线性回归训练准确率: {:.2f}%".format(traning_acc)) # 打印准确率 return loss_history, weight_history # 返回训练历史记录训练机器 loss_history, weight_history = linear_regression(X_train, y_train, weight, alpha, iterations)
|
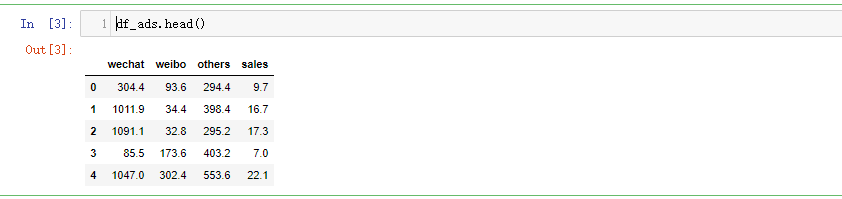
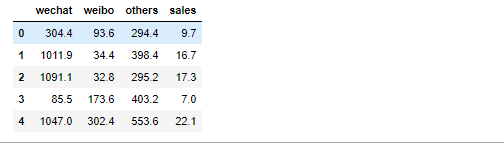 数据是代表微信公众号广告投放金额、微博广告投放金额、其他类型广告投放金额、商品销售额(千元)
数据是代表微信公众号广告投放金额、微博广告投放金额、其他类型广告投放金额、商品销售额(千元)
 相关性越高,颜色越深。此处的相关性分析结果很明确的告诉我们——将有限的金钱投放到微信公众号里面做广告是最为合理的选择。
相关性越高,颜色越深。此处的相关性分析结果很明确的告诉我们——将有限的金钱投放到微信公众号里面做广告是最为合理的选择。
 对于回归问题的数值类型数据集,机器学习模型所读入的规范格式应该是2D张量,也就是矩阵,其形状为(样本数,标签数)
对于回归问题的数值类型数据集,机器学习模型所读入的规范格式应该是2D张量,也就是矩阵,其形状为(样本数,标签数) 数据的结构从1D数组变成了有行有列的矩阵。
数据的结构从1D数组变成了有行有列的矩阵。 形状和之前的图像完全一致。
形状和之前的图像完全一致。
 下面画出当前回归函数的图像:
下面画出当前回归函数的图像:
 查看绘制的线性函数图像:
查看绘制的线性函数图像:

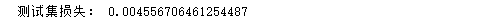 刚才所作的全部工作,就是利用机器学习的原理,基于线性回归模型,通过梯度下降,找到了两个最佳的参数值而已。
刚才所作的全部工作,就是利用机器学习的原理,基于线性回归模型,通过梯度下降,找到了两个最佳的参数值而已。




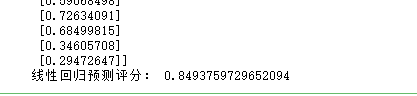 查看评分:
查看评分:
 查看权重与损失历史记录
查看权重与损失历史记录
【本文地址】